
Downtime at the Worst Time

Every CTF event has a few minutes of downtime as it opens, but RACTF 2021's downtime wasn't exactly conventional. Join us on a tail of duct tape engineering and how it saved the launch of RACTF 2021.
This post was co-written by Connor McFarlane from Inferno Communications, RACTF's infrastructure partner.
As I alluded to above, downtime is perfectly normal for the opening few minutes of a CTF. From infrastructure that wasn't designed to take the load to misconfigurations which aren't caught during the event preperations downtime is so common that it's on CTF bingo cards. RACTF has fallen victim to this before, at the start of RACTF 2020 we fell over a few minutes before the event started, and at the time we blamed this on an ongoing outage at our DDoS provider, Cloudflare.

Indeed, we attempted to bypass Cloudflare's proxy which only made the situation worse. Once things had calmed down we had another look at the Cloudflare outage and discovered it was completly unrelated. The outage was actually the result of the default number of workers in Nginx not being nearly high enough. Our systems couldn't keep up, not because they were too weak, but because of a configuration setting we weren't aware of at the time. Needless to say, our web server configuration recieved a thorough review after that incident.
Which, in a roundabout kind of way, brings me to RACTF 2021. For context, unlike 2020 which was run from Hetzner, RACTF 2021 was hosted from dedicated hardware hosted with Inferno Communications. This means we have a more direct responsibility for the management of the systems, but have a faster route to escalate issues.
As you can see from the monitoring graph below, everything was running well and users were getting ready to start enjoying the content we'd been putting together when all of a sudden the site stoped working.
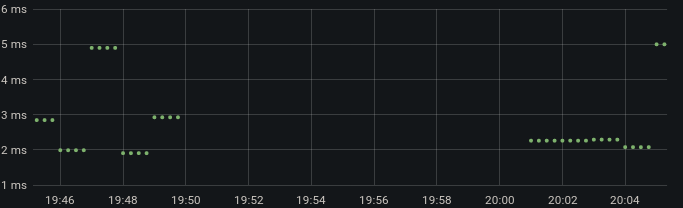
Oh no. Panic. We're 10 minutes out from everything starting and no one can compete. A lot of very loud swearing begins which is only drowned out by the sound of PagerDuty calling us to tell us we're down.

At this point we immediately reach out to Connor at Inferno who starts looking into the problem. A quick inspection of looking glass dashboards from tier 1 ISPs reveals that for some reason the IP range we are running out of has become unroutable. This rapidly develops into a call to the network operations center of our upstream ISP, Hurricane Electric. After a brief tense moment of dialing we are connected and informed that the issue is their side and not ours. So we're screwed, the event is minutes from starting and we're down because of something we've been told isn't our fault.
And then, all of a sudden, everything comes back. Even though Hurricane Electric were still looking into it, we were back up and the event could start on time. So what had happened? Well, when Connor was researching options around alternative transits, it was found to be cost prohibitive so an alternative was found. This would only need to be an emergency fallback, so what could be used instead? The free datacenter WiFi of course. That's right, for the first hour of RACTF 2021, all traffic was flowing via a BGP tunnel running on the free customer WiFi at the datacentre. Eventually, Inferno's infrastructure detected that Hurricane Electric were available again and failed the route back over to them, but a silly idea implemented as a stop gap had kept us on the air.
So what should you learn from this? An idea isn't stupid if it works. Alternatively that you should peer with more than one ISP.